قابلیتهای جدید در vSphere 6 مانند vMotion و FT برای 4vCPUs
VMware vSphere 6 Features: vMotion is one of the emblematic features of VMware Virtualization technology. vMotion is what many of the IT guys (including me) thinks is the “thing that got me hooked” into virtualization. It’s magic. vMotion has been here over a decade. Several improvements were already implemented since 2004 like storage vMotion (sVMotion), multiple nic vMotion, or a share-nothing vMotion which do not need shared storage to do a vMotion operation.
vSphere 6 Configuration Maximums and Platform Enhancements
vSphere 6 Doubles the vSphere Maximums!
- 64 hosts per cluster (vSphere 5.x it was 32)
- 8000 VMs (previously 4000)
- 480 CPUs (vSphere 5.x it was 320 CPUs)
- 12 TB of RAM (vSphere 5.x it was 4 TB of RAM)
- 2048 VMs per host (vSphere 5.x it was 512 VMs).

From VM perspective:
- Virtual hardware 11 (vmx-11) – newly released on vSphere 6
- 128vCPUs
- 4TB of RAM (NUMA aware)
- VDDM 1.1 GDI acceleration
- xHCI 1.0 controller compatible with OS X 10.8 + xHCI driver.

The VM compatibility level moves up to ESXi 6.0
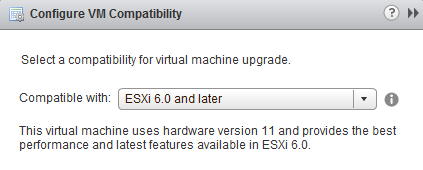
Update: It will be possible to use vSphere C# client to view functionality in virtual hardware 9, 10 and 11. Editing of settings will be possible in vmx8 and access to view settings virtual hardware 9 and higher.
Also the C# client in the final release of vSphere 6.0 will be able to manage vCenter.
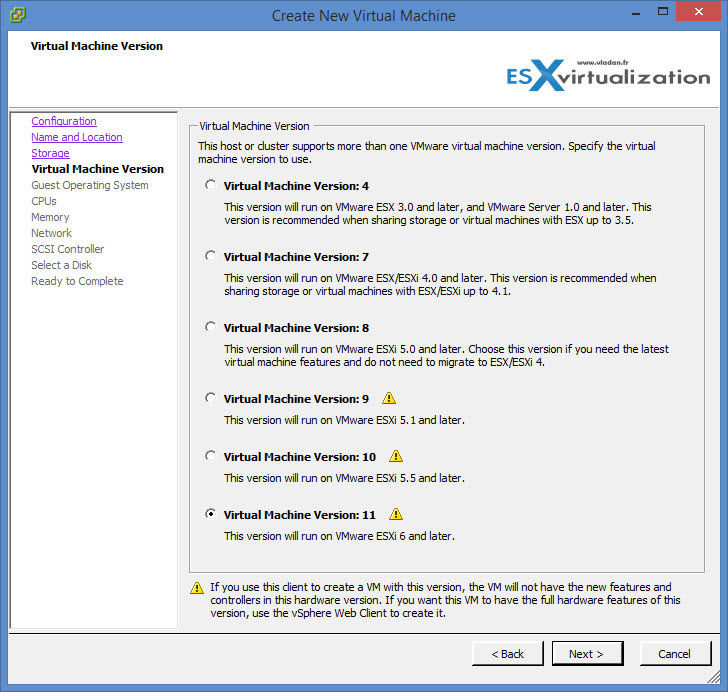
Here is a screenshot on the New VM creation wizard
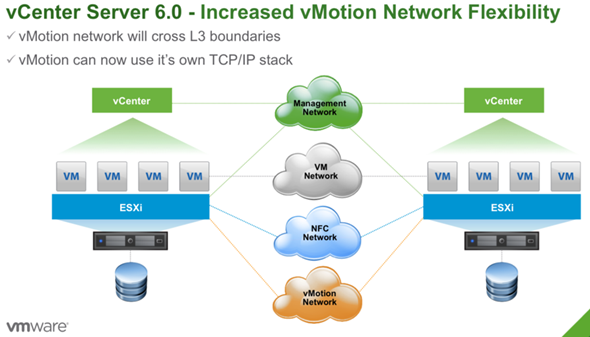
But this post will focus more on one of the major function which is vMotion. There is newly supported vMotion function which will allow VMs not only to be migrated within datacenter but also across datacenters, across country, across globe… here is what’s called Long distance vMotion.
Long Distance vMotion
vSphere 6 brings further enhancements into vMotion. In the first article that has been published with details allowed at that time – vMotion Enhancements in vSphere 6.0 – Long Distance vMotion, Across vSwitches and Across vCenters I briefly introduced the new details, but some of them were still under NDA at that time.
This is a game changer. Shifting workflows not only on premise but also off premise. IMHO this is huge and it opens very much other possibilities for DR plans and architecture. What if there is a huricane coming? No problem, just vMotion to another datacenter 500 miles away… Or is your local datacenter out of capacity? vMotion VMs elsewhere to free some capacity locally. Once more time the workflows became more portable, more agile, less tightened to the local only site.
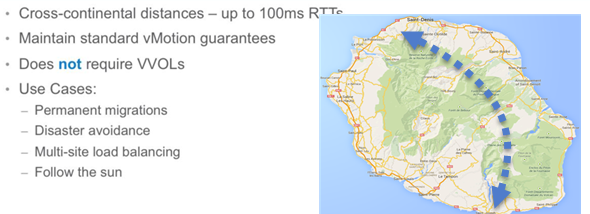
The major enhancement to vMotion this time (but it’s not the only one and it’s only from my point of view as it depends on what your interest is) is Long distance vMotion allowing to vMotion VMs from one datacenter to another (to remote site or cloud datacenter) and the requirements on this is to have a link with at least 100 ms RTT (previously 10 ms was necessary). As a network speed you will need 250 Mbps.
It means that it’s possible to vMotion a VM from one vCenter server to another vCenter server. The vMotion process is able to keep the VMs historical data (events, alarms, performance counters, etc.) and also a properties like DRS groups, HA settings, which are in relation and tighten to vCenter. It means that the VM can not only change compute (a host) but also network, management and storage – at the same time. (until now we could change host and storage during vMotion process – correct me if I’m wrong)
Requirements:
- vCenter 6 (both ends)
- Single SSO domain (same SSO domain to use the UI). With an API it’s possible to use different SSO domain.
- L2 connectivity for VM network
- vMotion Network
- 250 Mbps network bandwidth per vMotion operation
vMotion across vCenters:
- VM UUID is maintained across vCenter server instances
- Retain Alarms, Events, tak and history
- HA/DRS settings including Affinity/anti-affinity rules, isolation responses, automation level, star-up priority
- VM ressources (shares, reservations, limits)
- Maintain MAC address of Virtual NIC
- VM which leaves for another vCenter will keep its MAC address and this MAC address will not be reused in the source vCenter.
A datacenter was (until now) the highest point in the vCenter architecture…. But long distance vMotion can now get over it.
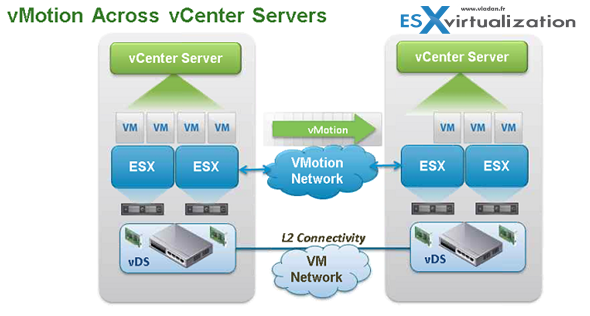
vShere 6 Features – vMotion across vCenters
With vSphere 6.0 vMotion can now do:
- vMotion across vCenters
- vMotion across virtual switches (VSS to VSS, VSS to VDS or VDS to VDS)
- vMotion across long distances and routed vMotion networks

Note:
VSS – standard switch
VDS – distributed switch
Previously vMotion mechanism allowed to vMotion a VM within single VSS or single vDS. It won’t be possible to vMotion back from VDS to VSS. The requirement for this is remaining the same – L2 connectivity. Both vCenters need to be connected via L3 network but the vMotion network needs to be a L3 type connection.
How it works?
The UUID of the VM remains the same (instant ID) no matter how many vMotion operations are done. What changes is the managed ID. vMotion will keep all the historical data, DRS rules, anti-affinity rules, events, alarms, task history and also HA properties are maintained. Standard vMotion compatibility checks are conducted before the vMotion occurs.
As a network latency, there shall fulfill the requirements of under 100 ms Round Trip Time (RTT) …..
No vVOLs requirement is necessary or shared storage requirements.
Requirements of Long-Distance vMotion
Same as for the vMotion across vCenter servers.
- L2 connectivity for VM network
- Same VM IP address available at the destination (if not the VM will have to be re-iped and will lose connectivity)
- vMotion network needs L3 connectivity
- 250 Mbps per vMotion operation
vMotion over Array Replication with VVols.
Note that I reported on VVols in this post in more details here. VVol SAN arrays can treat virtual disk which is stored on the array as an individual file (entity). VVol technology has granular control over VMDKs.
- VM-aware SAN/NAS systems
- Native representation of VMDKs on SAN/NAS
- New API for data operations at VMDK granularity
Advantage over classic LUN approach is that during replication is possible to granulary select only VM (not the full datastore). vMotion is already compatible with VVols, so if you have an array supporting VVols it’s possible to have vMotion over Active-Active replication. the A-A replicated storage appears as shared storage to the VM and the migration over A-A replication is classic vMotion.
Example can be when you have two sites, each with VVol capable array and at the same time you have setup a replication between those sites. Then:
- You can vMotion using the replication bits which are already on the destination site (remote site).
- Then VVols reverse the replication back to the main site to assure SLAs are still up and your workloads stays protected.
VVols are required for geographical distances.
The Active-Passive replication shall be supported in future releases of vSphere. vMotion over vSphere Replication (using async replication) is currently NOT supported.j But it’s high on the roadmap
vSphere 6.0 Fault Tolerance
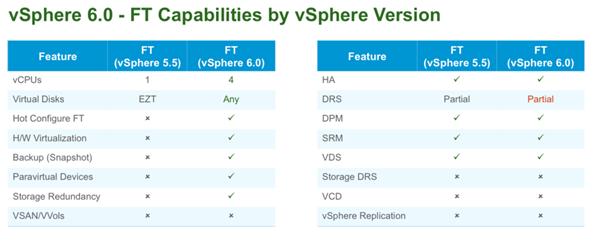
FT has 4vCPU VM support and 64 Gb of RAM per VM. The host limit with FT protected VMs is4. From the networking perspective it’s required to have 10gig network as single FT protected VM will use 1gb (or a bit more) of network bandwidth. Here are all the features of FT in VMware vSphere 6.
Update: vCenter server will be supported as FT VM in certain scenarios. The details and use cases were not uncovered yet!
FT Features:
- 4vCPU VMs can be protected by FT
- VMs with up to 64Gb of RAM
- Up to 4 FT protected VMs per host
- Hot configured FT possibility
- Enhanced virtual disk format support
- VADP support (can backup FT protected VMs now. Previously not possible)
The snapshot feature will however still remain. So no manual snapshots for VMs runing FT.
All those limits are configurable (by admin) via Advanced settings, so override is possible. (but it does not mean that it shall be done…)

FT Storage – FT VMs will need to have a secondary storage! This is new as previously you could use the same storage (for primary and secondary VMs). It’s a hard requirement.

The details are resumed in this screen:
The first resource which will gets exhausted by configuring VMs, it will be the network bandwidth. Concerning an overhead. Yes, there is an overhead. (more latency…). The best way is to try and see how it goes in your environment. If a protected VM runs out of bandwidth (or the storage is slower for one of the VMs) then the VM will slow down the protected VM so the secondary VM can keep up….
Recommendation is a 10Gb Nic dedicated for FT.
I still remember my VMworld session which details the vCPU FT in vSphere. In fact the demo I’ve seen showed 16 vCPU VM being protected by Fault Tolerance. It works but with some price to pay – quite big overhead. The technology which was always present in FT (vLockstep) has evolving as well, and has been replaced by another technology called fast-checkpointing.
Fault Tolerance, as you probably know provides continuous availability. It offers zero downtime, zero data loss, there is no temporary TCP disconnections. FT is complete transparent to guest OS, which don’t know that is actually mirrored and that there is another (shadow) VM following in vlockstep few milliseconds behind what’s happening in the protected VM.
FT protects VM, which survive server failures. FT requiring absolutely no configuration of the Guest OS or the in-guest software. (Right click VM > FT > Turn ON FT…)

Today’s limit of single vCPU for VMs protected by FT will be lifted when vSphere 6.0 will become available.
Use cases:
- Protection for high performance, multi-vCPU VMs
It should satisfy 90% of the current workloads, which is a lot as current limitation on single vCPU turns off many customers which has their VMs designed to support more demanding workflows than that. New, more scalable technology which uses fast check-pointing to keep primary and secondary VM in sync will. Stay tuned for further details…
High Availability Enhancements
vSphere HA in vSphere 6 got enhanced as well and introduces the component protection. It detects for example that the underlying storage has problems, so it restarts the VM on another host where it finds suitable storage. It detects All path down (APD), and Permanent device lost (PDL) situations.
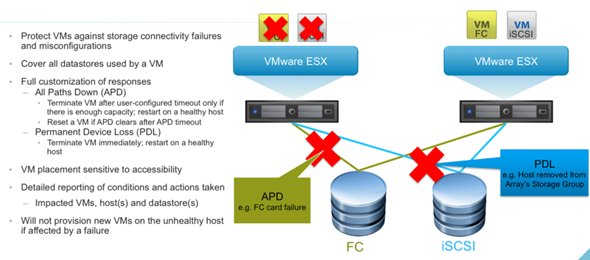
It will be an automated response to APD or PDL situations.
vSphere Client Management
some features in the hardware versions 10 and 11 are read only… see the table below….

vSphere 6 Network I/O control version 3
NIOC v3 brings new enhancements. If you’ll need to upgrade an existing environment (from v2) you’ll first have to upgrade vDS to v3 and then you’ll have v3 of NIOC. It’s possible to reserve bandwidth and guarantee SLAs.
It’s applied at the distributed port group level or at the vNic level and enables bandwidth to be guaranteed at the virtual nic interface on a VM. (there is a reservation set on the vNIC in the VM). Usual use case would be for service provides wanting to guarantee network bandwidth between multiple tenants.

Check the vSphere 6 page for further details, How-to, videos and news…