مقدمه ای بر SQL Server Cluster
The options for high availability can get confusing. I was lucky enough to begin working with SQL Server clusters early in my career, but many people have a hard time finding simple information on what a cluster does and the most common gotchas when planning a cluster.
Today, I’ll tell you what clusters are, what they’re good for, and why I like to plan out my clusters in a very specific way. I’ll also give an overview of how clustering relates to the AlwaysOn Availability Groups feature in SQL Server 2012, and wrap up with frequently asked questions about clustering SQL Server.
WHAT TYPE OF SQL CLUSTERING ARE WE TALKING ABOUT?
There are lots of types of clusters out there. When we cluster SQL Server, we install one or more SQL Server instances into a Windows Failover Cluster. In this post I’m talking specifically about clustering SQL Server 2005 or later using Windows Server 2008 or later.
Key Concept: A Windows Failover Cluster uses shared storage– typically, this shared storage is on a SAN. When a SQL Server instance is installed on the cluster, system and user databases are required to be on the shared storage. That allows the cluster to move the SQL instance to any server (or “node”) in the cluster whenever you request, or if one of the nodes is having a problem. There is only one copy of the data, but the network name and SQL Server service for the instance can be made active from any cluster node.
Translation: A failover cluster basically gives you the ability to have all the data for a SQL Server instance installed in something like a share that can be accessed from different servers. It will always have the same instance name, SQL Agent jobs, Linked Servers and Logins wherever you bring it up. You can even make it always use the same IPAddress and port– so no users of the SQL Server have to know where it is at any given time.
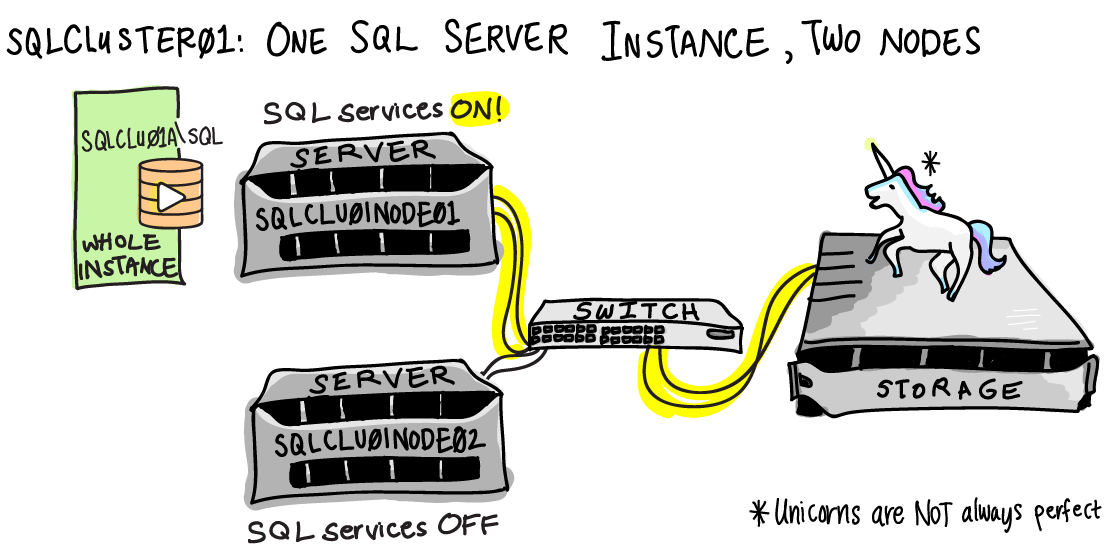
Here is a diagram of a SQL Server cluster. The cluster is named SQLCLUSTER01. It has two nodes (servers), which are named SQLCLU01NODE01 and SQLCLU01NODE02. People connect to the SQL Server instance at SQLCLU01A\SQL. The instance has been configured on port 1433.
Oh no! There’s been a failure in our environment!
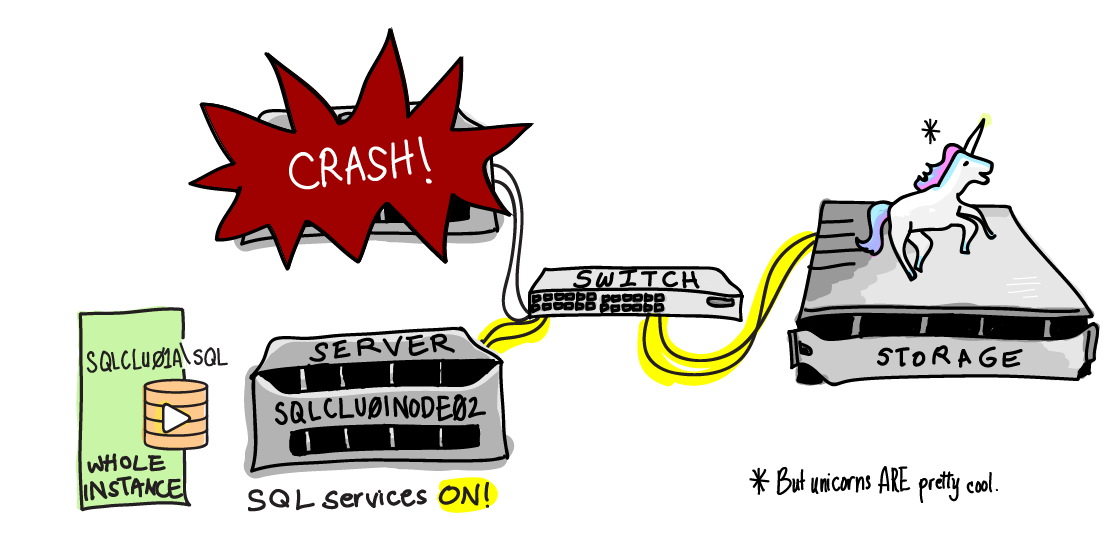
Here’s what happened.
The SQLCLU01NODE01 server crashed unexpectedly. When this happened, the Windows Failover Cluster service saw that it went offline. It brought up the SQL Server services on SQLCLU01NODE02. The SQLCLU01A\SQL instance started up and connected to all the same databases on the shared storage– there’s one copy of the data, and it doesn’t move. As part of the SQL Server startup, any transactions that were in flight and had not committed at the time of the crash were rolled back.
While this automatic failover was occurring, users could not connect to the SQLCLU01A\SQL instance. However, after it came back up they were able to resume operations as normal, and had no idea that a server was still offline.
WHY YOU CARE ABOUT SQL SERVER CLUSTERING
If you’re a business owner, manager, or DBA, you care about clustering because it helps keep your applications online more of the time— when done properly, it makes your database highly available.
Here are some ways that clustering makes your life easier:
- Hardware failures are a nightmare on standalone servers. If a server starts having problems in a failover cluster, you can easily run your SQL Server instance from another node while you resolve the issue.
- Applying security patches on a standalone server can be very tedious and annoying to the business: the SQL Server is offline while you wait for the server to reboot. By using failover clustering, you can apply patches with only brief downtimes for your application as you move your SQL Server instance to a different node.
- Failover clusters can also give you an additional tool in your troubleshooting toolkit. Example: if you start seeing high latency when using storage and you’ve ruled out all the immediate candidates, you can fail to another node to try to rule out if it’s a problem with a per-node component like an HBA.
- Clustering is transparent to the calling application. Lots of things with SQL Server “just work” with clustering, whereas they’re a little harder with other alternatives. With clustering, all of my databases, logins, agent jobs, and everything else that’s in my SQL Server instance fail over and come up together as a single unit— I don’t have to script or configure any of that. I can also cluster my distributed transaction coordinator and fail it over with my instance as well.
GOTCHAS AND NOTES FOR PLANNING A SQL CLUSTER
Know What Clustering SQL Server Doesn’t Do
The first gotcha is to be aware of what a failover cluster won’t help you with.
Clustering won’t improve your performance, unless you’re moving to more powerful servers or faster storage at the same time you implement clustering. If you’ve been on local storage, don’t assume moving to a SAN means a nirvana of performance. Also, clustering doesn’t guarantee that everything involved in your SAN is redundant! If your storage goes offline, your database goes too.
Clustering doesn’t save you space or effort for backups or maintenance. You still need to do all of your maintenance as normal.
Clustering also won’t help you scale out your reads. While a SQL Server instance can run on any node in the cluster, the instance is only started on one node at a time. That storage can’t be read by anyone else on the cluster.
Finally, clusters won’t give you 100% uptime. There are periods of downtime when your SQL Server instance is “failing over”, or moving between nodes.
Invest Time Determining the Right Naming Convention
You have a lot of names involved in a cluster: a name for the cluster itself, names for each of the servers in the cluster, and names for each SQL instance in the cluster. This can get confusing because you can use any of these names later on when connecting with Remote Desktop– so if you’re not careful, there may be times when you’re not entirely sure what server you’re logged onto! I have two general rules for naming:
First, make sure it’s obvious from the name what type of component it is– whether it’s a cluster, physical server, a SQL Server instance, or a Distributed Transaction Coordinator. I also recommend installing BGINFO to display the server name on the desktop for every server in the cluster.
Second, name everything so that if you later add further nodes or install another SQL Server instance onto the cluster, the names will be consistent.
Avoid Putting Too Many Nodes in One SQL Cluster
I prefer to have only two or three nodes in a cluster. For example, if I need to cluster five SQL Server instances, I would put them in two failover clusters.
This requires a few extra names and IP Addresses overall, but I prefer this for management reasons. When you apply patches or upgrades, you must make sure that each service on your cluster runs on each node successfully after you’ve applied the change. Having a smaller cluster means you don’t need to fail your instance over as many times after a change.
Don’t Assume Your Applications Will Reconnect Properly After Failover
Even though your SQL Server instance will come up with the same network name and IPAddress (if not using DHCP), many applications aren’t written to continue gracefully if the database server goes offline briefly.
Include application testing with your migration to a failover cluster. Even though the application doesn’t know it’s talking to a cluster (it’s a connection string like any other), it may not reconnect after a failover. I worked with one application where everything worked fine after a failover, except web servers stopped writing their log data to a database because they weren’t designed to retry after a connection failure. The data was written asynchronously and didn’t cause any failures that impacted users, but the issue wasn’t noticed immediately and caused the loss of some trending data.
“Active Active” Can Be Useful
My ideal cluster layout to work with is a two node cluster with identical hardware and two SQL Server instances on it. This is commonly called “Active Active” clustering, but that term is technically a no-no. Officially this is called a “Multi-Instance Failover Cluster.” Not quite as catchy, is it?
Many people think the ideal situation is to put their most important SQL Server instance on a two node cluster and leave the second node ready, waiting, and idle. So, why do I want a second SQL Server instance?
I like to put my critical, heavy hitter database on one of those instances in the cluster. I then want to take a couple of less critical, less busy databases and put them on the second instance. The perfect examples are logging databases. There are two requirements for these databases: first, they can’t require a large amount of memory or processor use to run well, because I absolutely have to know that these two instances can run successfully at peak load on a single node if required. Second, the databases on the “quiet” instance shouldn’t cause the whole application to go offline if they aren’t available.
Why do I like having a “quiet” instance? Well, whenever I need to apply updates to Windows or SQL Server, this is the canary I send into the coal mine first. You can perform rolling upgrades with failover clusters, which is great. But it’s even better to know that the first instance you fail over onto an upgraded node won’t take absolutely everything down if it has a problem.
Notes: Because of licensing costs, this option won’t always be realistic. If you go this route you have to make sure everything can stay within SLA if it has to run on a single node at your busiest times– don’t overload that “quiet” instance!
Re-Evaluate your SQL Server Configuration Settings
Revisit your configuration settings as part of your planning. For example, on a multi-instance cluster, you use the minimum memory setting for SQL Server to configure how your instances will balance their memory usage if they are on the same node.
DO I HAVE TO USE CLUSTERING TO USE AVAILABILITY GROUPS IN SQL SERVER 2012?
This is an interesting question– don’t let it confuse you. We have a very cool new feature calledAvailability Groups coming in SQL Server 2012, which does offer awesome scale-out read functionality. You’ll read in many places that it “requires Failover Clustering.”
This is true. In order to use the Availability Group feature in SQL Server 2012, the Failover Clustering feature must be enabled in Windows. If you’re using Windows Server 2008 or prior, this feature is only available in Datacenter and Enterprise edition of Windows Server, so that feature isn’t free. This feature is now included in Windows Server 2012 for all editions.
But wait, there’s a catch! Even though you’re enabling the Failover Cluster feature, you are NOTrequired to have shared storage to use Availability Groups. You have the option to use a Failover Cluster in an Availability Group, but you can also run your Availability Groups with entirely independent storage subsystems if you desire. The feature is required because no matter what, Availability Groups will use parts of the Failover Clustering feature to manage a virtual network name and IP Address.
FREQUENTLY ASKED QUESTIONS FOR CLUSTERING SQL SERVER
Q: Can I install every SQL Server component on my cluster?
A: Nope. SQL Server Integration Services is not “cluster-aware” and can’t fail back and forth with your cluster.
Q: How long does it take to fail over?
A: There are several factors to consider in failover time. There’s the time for the SQL Server Instance’s service to go down on one node, be initiated on another node, and start up. This time for instances to start and stop includes normal database recovery times. If you need to keep failovers within an SLA, you’ll want to test failover times in a planned downtime, but also estimate in how long failover mightbe if it happened at peak load.
Q: Can I cluster a virtualized server?
A: Yes, you can create failover clusters with virtual servers with VMware or Hyper-V, and install SQL Server into it. I think this is great for learning and testing, but I’m not crazy about this for production environments. Read more here.
Q: Why do you make such a big deal about the shared storage?
A: Because not everyone has robust shared storage available. You want to make sure you’re using shared storage that has redundancy in all the right places, because in a failover cluster shared storage is a single point of failure, no matter how magical the SAN seems. This also means that if your data is corrupted, it’s going to be corrupted no matter which node you access it from.
Q: What’s the minimum number of nodes in a failover cluster?
A: One. This is called a single-node cluster. This is useful for testing purposes and in case you have a two node cluster and need to do a work on a node. You can evict a node without destroying the cluster.
Q: Can I use geo-clustering for Disaster Recovery?
A: Yes, but it requires some fancy setup. Most SQL Server clusters are installed in the same subnet in a single datacenter and are suitable for high availability. If you want to look into multi-site clustering, “geo-clustering” became available with SQL Server 2008, and is being enhanced in SQL Server 2012. Note: you’ll need storage magic like SAN replication to get your Geo-cluster on.
Q: Does it matter which version of Windows I use?
A: Yes, it matters a lot. Plan to install your Windows Failover Cluster on the most recent version of Windows Server, and you need Enterprise or Datacenter edition. If you must use an older version of Windows, make sure it’s at least Server 2008 with the latest service packs installed. The Failover Clustering Component of Windows was rewritten with Server 2008, so if you run on older versions you’ll have fewer features and you’ll be stuck chasing old problems.
Q: What is Quorum?
A: Quorum is a count of voting members— a quorum is a way of taking attendance of cluster members who are present. The cluster uses a quorum to determine who should be online. Read more about quorum here.