Fault tolerance به قابلیت یک سیستم برای ادامه عملکرد صحیح و حفظ کارایی خود حتی در مواجهه با مشکلات، خرابیها، یا خطاهای نرمافزاری و سختافزاری اطلاق میشود. این مفهوم به ویژه در طراحی سیستمهای بحرانی و حیاتی، مانند سیستمهای کامپیوتری، شبکهها، و زیرساختهای فناوری اطلاعات، اهمیت دارد. هدف از طراحی سیستمهای با Fault tolerance این است که از اختلالات و توقفهای غیرمنتظره جلوگیری شود و سیستم همچنان بتواند به کار خود ادامه دهد.
به تعبیری دیگر، تحمل خطا ، عدم تأخير در ارائه سرويس و قدرت تحمل در هنگام بروز مشكل و خطاهای عمدتا سخت افزاری است بعبارت ديگر Fault tolerance (به اختصار FT) قابليتی است در سيستم عامل که می تواند هنگام بروز مشكلات از تجهيزات جايگزين استفاده کرده و بدون تأخير (يا با تأخير بسيار کوتاه ) بطور خودکار به سرويس دهی ادامه دهد. نکته اصلی درFT این است که هنگام بروز خطا اولا زمان قطعی سرويس صفر يا بسيار کوتاه بوده و ثانيا عمليات جايگزينی بدون عوامل انسانی و بطور خودکار صورت می گيرد Admin در فرصت مناسب می تواند عيوب را بررسی و رفع کند. فرض کنید که يك سرور داريم که نوع آن هم زیاد مهم نیست و این سرور با يك کارت شبكه (NIC) به شبكه متصل شده و کامپيوترهای موجود از آن سرويس می گيرند. اگر برای کارت شبكه يا خط متصل به آن اتفاقی بيافتد بديهی است که کلیه سرويسها قطع می شوند و برای اینکه دچار قطعی نشویم بايد:
1- شرايط سخت افزاری لازم را مهيا کنيد يعنی از ابتدا دو عدد کارت شبکه روی سیستم نصب کنید.
2- سیستم عاملی را انتخاب کنید که دارای قابلیت FT در این زمینه باشد. سيستم عامل در شرايط عادی اطلاعات را تقسيم کرده و از هر دو کارت برای ارسال و دريافت استفاده می کند (که البته باعث افزايش سرعت نيز می شود) حال اگر به هر دليل يكی از کارتها از کار بيفتد ، سيستم از کارت ديگری برای ادامه کار استفاده می کند.
ویژگیها و مزایای Fault Tolerance:
- پایداری و قابلیت اطمینان بالا: سیستمهای با Fault tolerance قادر به ارائه خدمات بدون توقف در شرایطی که برخی از اجزای آنها دچار مشکل میشوند. این ویژگی برای سیستمهای حیاتی مانند پایگاههای داده، سیستمهای پردازش تراکنش و خدمات ابری بسیار مهم است.
- افزایش در دسترسی: با استفاده از تکنیکهای Fault tolerance، میتوان از کاهش زمانهای توقف و افزایش دسترسی به خدمات اطمینان حاصل کرد. این به ویژه در سیستمهای آنلاین و خدمات 24/7 اهمیت دارد.
- جلوگیری از خسارات مالی و عملیاتی: با کاهش زمانهای توقف و افزایش قابلیت دسترسی، سازمانها میتوانند از خسارات مالی و عملیاتی ناشی از خرابیهای سیستم جلوگیری کنند.
- مقیاسپذیری: سیستمهای Fault-tolerant میتوانند به طور مؤثر با افزایش حجم کار و تقاضاهای جدید مقابله کنند بدون اینکه عملکرد آنها تحت تأثیر قرار گیرد.
تکنیکهای اصلی Fault Tolerance:
- Redundancy (اضافهکاری): استفاده از اجزای اضافی که به صورت همزمان با اجزای اصلی کار میکنند. در صورت خرابی یکی از اجزا، اجزای اضافی قادر به ادامه عملیات هستند. این میتواند شامل سختافزار اضافی، سرویسهای اضافی، و مسیرهای اضافی در شبکه باشد.
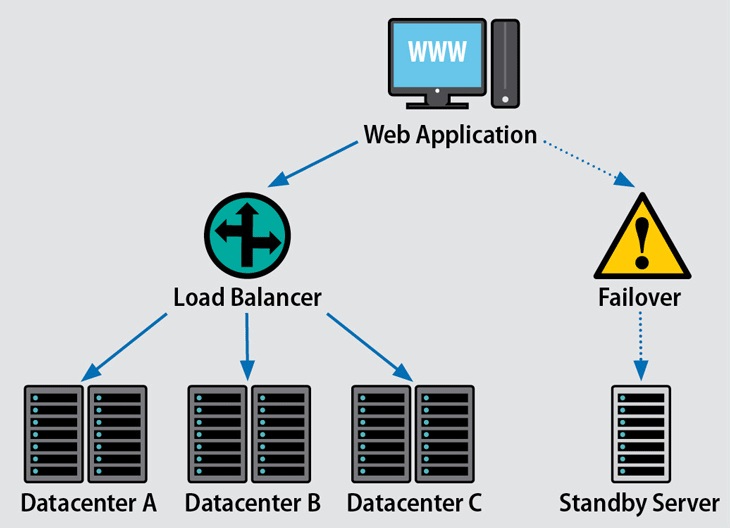
- Failover (انتقال به حالت آمادهبهکار): مکانیزمهایی که به صورت خودکار عملیات را به یک سیستم یا جزء پشتیبان در صورت خرابی جزء اصلی منتقل میکنند. این تکنیک معمولاً در سرورها و سیستمهای ذخیرهسازی مورد استفاده قرار میگیرد.
- Checkpointing (ایجاد نقاط بازگشت): ذخیرهسازی وضعیت سیستم در نقاط خاص به طوری که در صورت بروز خطا، سیستم بتواند از آخرین نقطه ذخیره شده به کار خود ادامه دهد.
- Replication (تکرار): ایجاد نسخههای مختلف از دادهها یا سیستمها در مکانهای مختلف به طوری که در صورت خرابی یکی از نسخهها، نسخههای دیگر همچنان فعال و در دسترس باشند.
- Error Detection and Correction (تشخیص و تصحیح خطا): استفاده از الگوریتمها و روشهای مختلف برای شناسایی و تصحیح خطاها در دادهها و فرآیندها.
کاربردها:
- سیستمهای بانکی و مالی: برای حفظ در دسترس بودن خدمات و جلوگیری از توقفهای غیرمنتظره که ممکن است به مشکلات مالی منجر شود.
- شبکههای مخابراتی: برای تضمین ادامه فعالیت خدمات تلفن و اینترنت حتی در صورت خرابی تجهیزات یا خطوط ارتباطی.
- پایگاههای داده: برای اطمینان از دسترسی به دادهها و جلوگیری از از دست رفتن اطلاعات در صورت خرابی سیستم.
- خدمات ابری و دیتا سنترها: برای حفظ قابلیت دسترسی و عملکرد خدمات ابری و دیتا سنترها در مواجهه با خرابیهای سختافزاری و نرمافزاری.
نتیجهگیری:
Fault tolerance به طراحی و پیادهسازی سیستمهایی اشاره دارد که قادر به ادامه عملکرد صحیح و حفظ کارایی خود حتی در مواجهه با مشکلات و خرابیها هستند. با استفاده از تکنیکهای مختلف مانند redundancy، failover، و replication، میتوان از اختلالات و توقفهای غیرمنتظره جلوگیری کرد و به پایداری و قابلیت اطمینان بالای سیستمها دست یافت. این مفهوم به ویژه در سیستمهای حیاتی و خدمات مهم که نیاز به دسترسی مستمر و بدون وقفه دارند، بسیار اهمیت دارد.